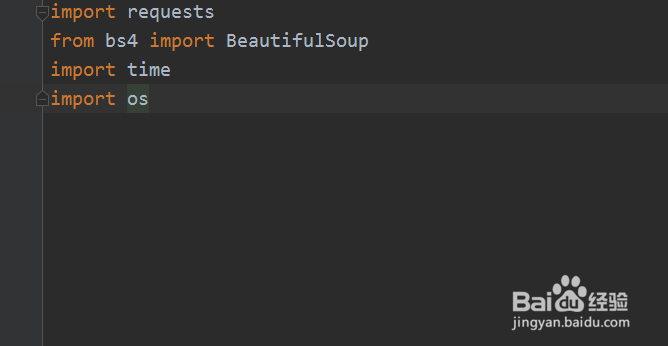
1、打开pycharm工具,新建Python文件;在文件中,依次导入requests和BeautifulSoup
2、查找一个网站地址,然后赋值给变量url,作为解析数据和标签的来源

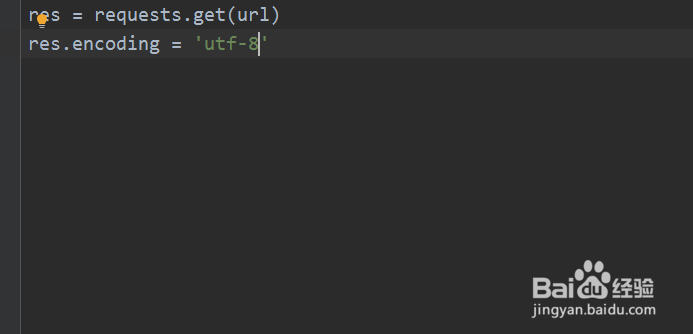
3、调用requests.get()方法获取网站的数据,并设置编码格式为utf-8
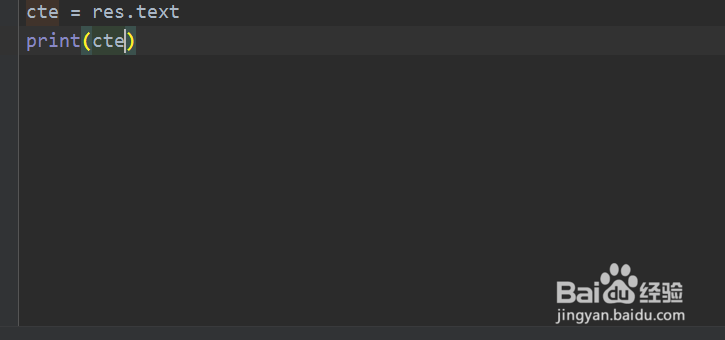
4、获取请求成功后的text属性,赋值给变量cte并打印值
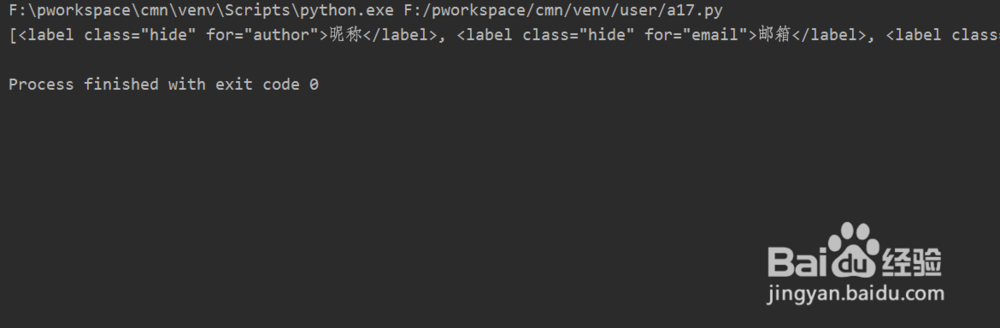
5、保存代码并运行Python文件,可以查看到控制台打印一些HTML标签和数据
6、调用BeautifulSoup中的方法对HTML进行解析,然后使用find_all()方法查找label标签
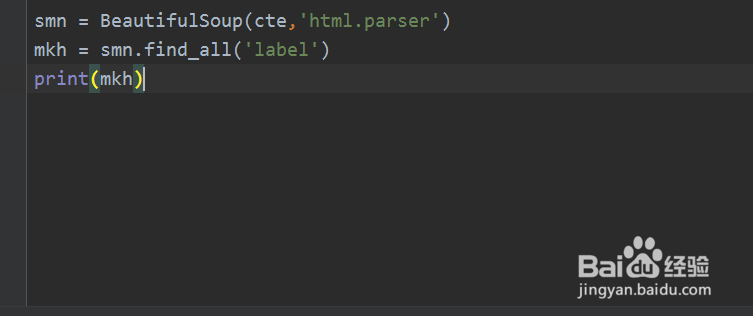
7、再次保存代码并运行Python文件,可以查找到所有label标签元素和对应的数据